David Picard
IMAGINE/A3SI/LIGM, École Nationale des Ponts et Chaussées Email / GitHub / Google Scholar / Resume / Teaching
|

|
ResearchMy research interests include machine learning for computer vision. I am interested in all sorts of things both on the more theoretical side (with prior works on Kernel methods and now deep learning) and applications (with prior works on human analysis and visual search). I am into image generative models (any architecture/loss) at the moment, but more for the unsupervised learning tools aspect. |
|
PhD Students
Current
- Julien Lalanne, 2025-2028, Generative Modeling of Spatial Processes for 3D Geophysical Data Interpolation in Offshore Windfarm Site Characterization, With Lina-Maria Guayacan-Carrillo and J-M Pereira at Navier, and Lionel Boillot and Leon Barens at TotalEnergies Renouvelables
- Adrien Ramanana-Rahary, 2025-2028, Generative world models, with Patrick Pérez at Kyutai
- Salma Galaaoui, 2024-2027, Human pose tracking and forecasting, with Eduardo Valle and Nermin Samet at Valeo
- Lucas Degeorge, 2024-2027, Multimodal content generation, Supervised by Vicky Kalogeiton at LIX
- Arijit Ghosh, 2024-2027, Generalization in image generative models, with Vicky Kalogeiton at LIX
Alumni
- Simon Lepage, 2022-2025, Transformers for recommender system and generative recommendation, with Jérémie Mary at Criteo
- Nicolas Dufour, 2021-2025, Controlability and efficiency in generative models, with Vicky Kalogeiton at École Polytechnique
- Natacha Luka, 2024, Cross-modal Representation Learning, with Romain Negrel at ESIEE
- Yue Zhu, 2024, Interactive 3D estimation of human posture in the working environment using deep neural networks
- Grégoire Petit, 2020-2023, Examplar Free Class Incremental Learning, with Adrian Popescu and Bertrand Delezoide at CEA
- Thibaut Issenhuth, 2023, Interactive Generative Models, with Jérémie Mary at Criteo
- Victor Besnier, 2022, Safety in Deep Learning based Computer Vision, with Alexandre Briot and Andrei Bursuc at Valeo
- Marie-Morgane Paumard, 2020, Solving jigsaw puzzles with Deep Learning (with H. Tabia)
- Pierre Jacob, 2020, High-order statistics for representation learning (with A. Histace and E. Klein)
- Diogo Luvizon, 2019, 2D/3D Pose Estimation and Action Recognition (with H. Tabia), now at Samsung
- Jérôme Fellus, 2017, Machine learning using asynchronous gossip exchange (with P.H. Gosselin), now postdoc at Irisa
- Romain Negrel, 2014, Representation learning for image retrieval (with P.H. Gosselin), now associate prof at Esiee
Recent publications
Full list: scholar / dblp / hal
|
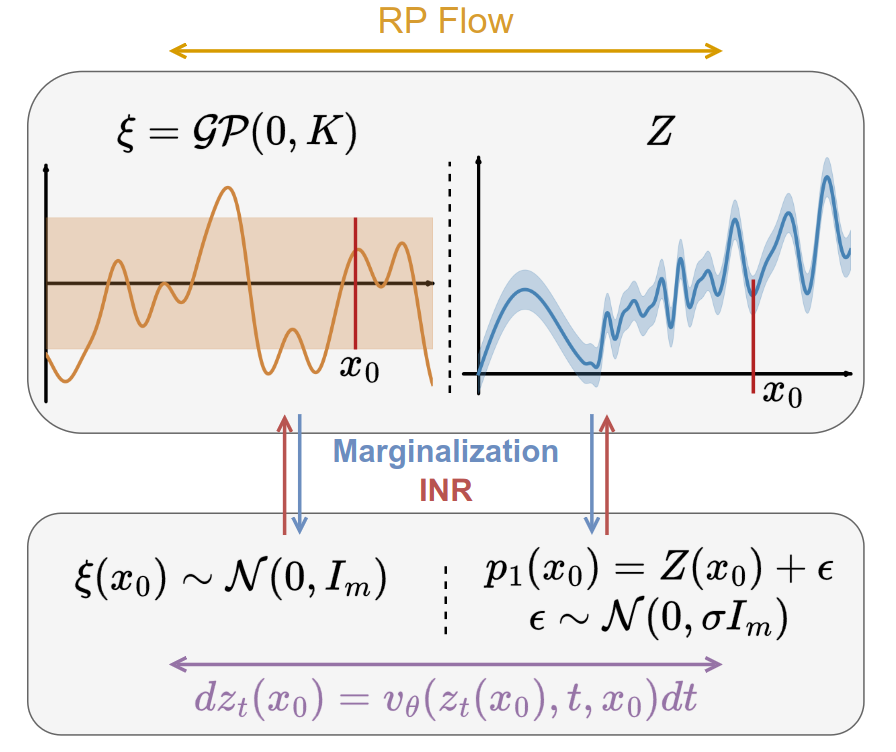
Random Process Flow Matching: Generative Implicit Representations of Multivariate Random FieldsJulien Lalanne, David Picard, Lionel Boillot, Lina-María Guayacan-Carrillo, Leon Barens, Jean-Michel Pereira ICML, 2026 arxiv / Generative modeling provides a powerful framework for learning data distributions. These models initially relied on probabilistic methods such as Gaussian Processes (GP) for uncertainty-aware predictions and shifted towards larger trainable models to learn more complex distributions. In this work, we introduce Random Process (RP) Flow, a Flow Matching-based framework that represents the vector field as a neural implicit function. Unlike modern generative methods, our setting involves a single observed field, from which only sparse measurements are available. RP Flow uses Random Fourier Features to learn an implicit signal representation that can be queried at any arbitrary location from a limited set of observations, while encoding uncertainty through ensemble sampling. We propose constructing a Bayesian posterior by GP regression in the source space to generate high-quality samples. |

|
MIRO: MultI-Reward cOnditioned pretraining improves T2I quality and efficiencyNicolas Dufour, Lucas Degeorge, Arijit Ghosh, Vicky Kalogeiton, David Picard ICML, 2026 arxiv / The default paradigm of post-training text-to-image generators includes post-hoc selection of generated images, and subsequent training with one reward model to align the generator to the reward, typically user preference. This discards informative data as well as optimizes only for a single reward, hence harming diversity, semantic fidelity and efficiency. Instead, we propose MIRO, a method that conditions the model on multiple rewards during training, thus letting the model learn user preferences directly. MIRO pre-training both improves the visual quality of the generated images and speeds up the training, achieving state of the art on the GenEval compositional benchmark and user-preference scores (PickAScore, ImageReward, HPSv2). |
|
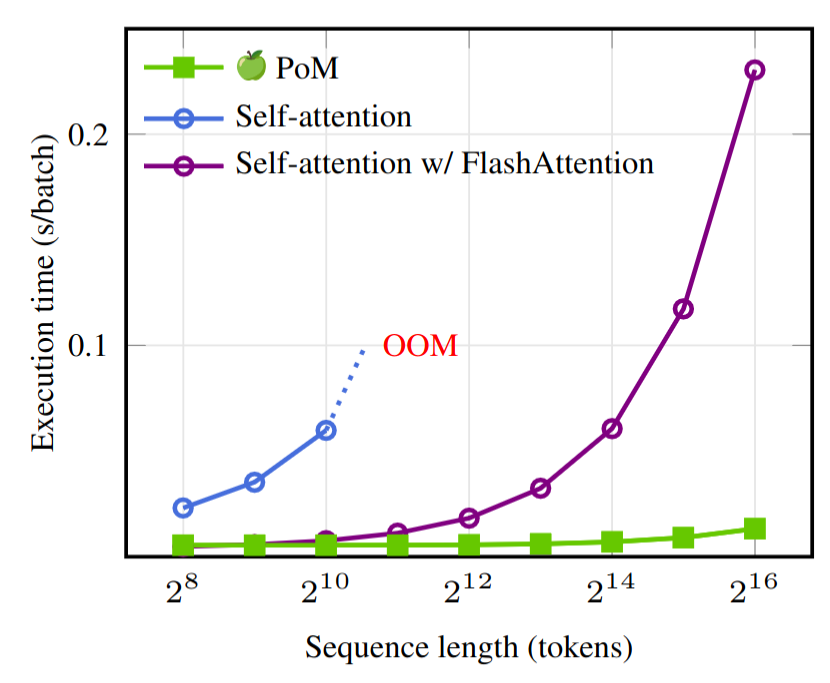
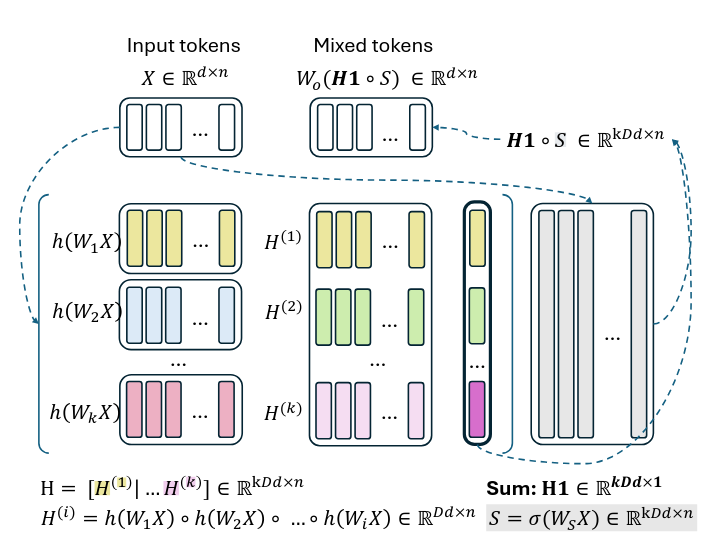
PoM: A Linear-Time Replacement for Attention with the Polynomial MixerDavid Picard, Nicolas Dufour, Lucas Degeorge, Arijit Ghosh, Davide Allegro, Tom Ravaud, Yohann Perron, Corentin Sautier, Zeynep Sonat Baltaci, Fei Meng, Syrine Kalleli, Marta López-Rauhut, Thibaut Loiseau, Ségolène Albouy, Raphael Baena, Elliot Vincent, Loic Landrieu CVPR Findings, 2026 arxiv / code / This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. |
|
Polynomial Mixing for Efficient Self-supervised Speech EncodersEva Feillet, Ryan Whetten, David Picard, Alexandre Allauzen ICASSP, 2026 arxiv / State-of-the-art speech-to-text models typically employ Transformer-based encoders that model token dependencies via self-attention mechanisms. However, the quadratic complexity of self-attention in both memory and computation imposes significant constraints on scalability. In this work, we propose a novel token-mixing mechanism, the Polynomial Mixer (PoM), that computes a polynomial representation of the input with linear complexity with respect to the input sequence length. We integrate PoM into a self-supervised speech representation learning framework based on BEST-RQ and evaluate its performance on downstream speech recognition tasks. |
|
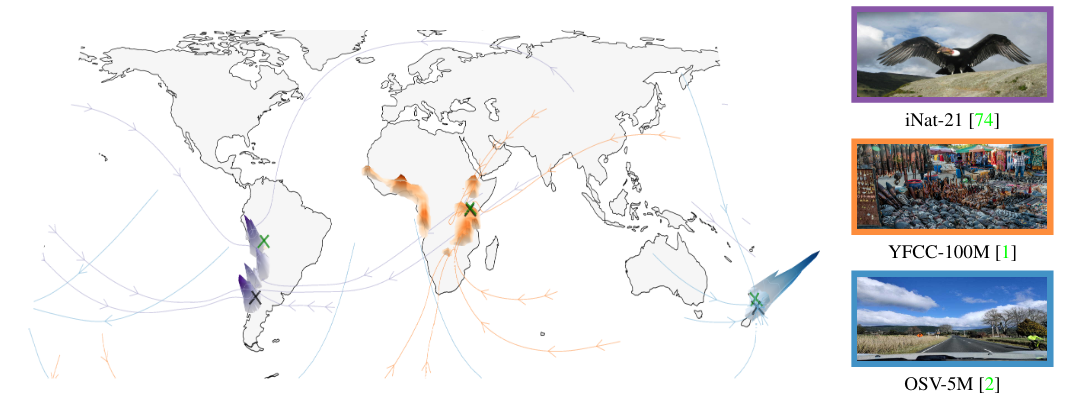
Around the World in 80 Timesteps: A Generative Approach to Global Visual GeolocationNicolas Dufour, David Picard, Vicky Kalogeiton, Loic Landrieu CVPR, 2025 arxiv / code / Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth’s surface. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. |

|
Analysis of Classifier-Free Guidance Weight SchedulersXi Wang, Nicolas Dufour, Nefeli Andreou, Marie-Paule Cani, Victoria Fernandez Abrevaya, David Picard, Vicky Kalogeiton TMLR, 2024 arxiv / Classifier-Free Guidance (CFG) enhances the quality and condition adherence of text-to-image diffusion models. Recent works vary the weights throughout the diffusion process, reporting superior results but without providing any rationale or analysis. By conducting comprehensive experiments, this paper provides insights into CFG weight schedulers. Our findings suggest that simple, monotonically increasing weight schedulers consistently lead to improved performances. In addition, more complex parametrized schedulers can be optimized for further improvement, but do not generalize across different models and tasks. |

|
Don’t drop your samples! Coherence-aware training benefits Conditional diffusionNicolas Dufour, Victor Besnier, Vicky Kalogeiton, David Picard CVPR, 2024 arxiv / code / We propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. |
|
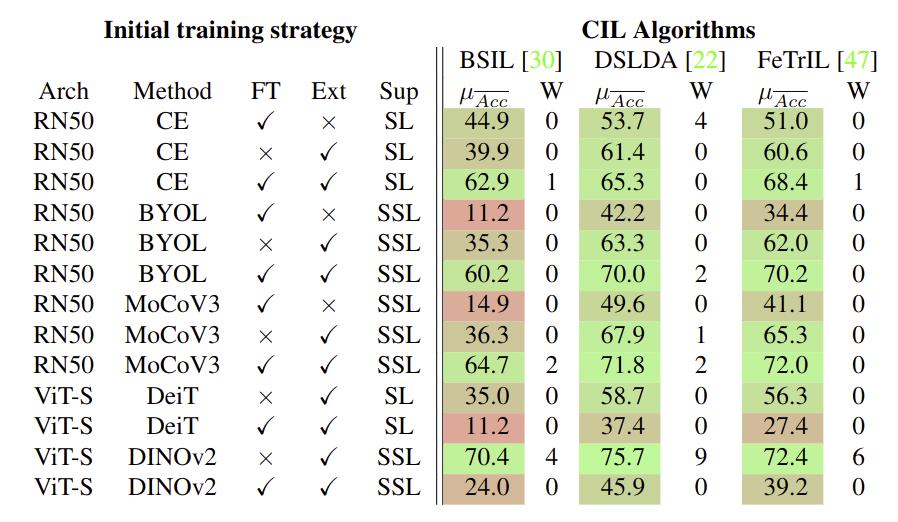
An Analysis of Initial Training Strategies for Exemplar-Free Class-Incremental LearningGrégoire Petit, Michaël Soumm, Eva Feillet, Adrian Popescu, Bertrand Delezoide, David Picard, Céline Hudelot WACV, 2024 arxiv / Class-Incremental Learning (CIL) aims to build classification models from data streams. At each step of the CIL process, new classes must be integrated into the model. Due to catastrophic forgetting, CIL is particularly challenging when examples from past classes cannot be stored, the case on which we focus here. To date, most approaches are based exclusively on the target dataset of the CIL process. However, the use of models pre-trained in a self-supervised way on large amounts of data has recently gained momentum. The initial model of the CIL process may only use the first batch of the target dataset, or also use pre-trained weights obtained on an auxiliary dataset. The choice between these two initial learning strategies can significantly influence the performance of the incremental learning model, but has not yet been studied in depth. Performance is also influenced by the choice of the CIL algorithm, the neural architecture, the nature of the target task, the distribution of classes in the stream and the number of examples available for learning. We conduct a comprehensive experimental study to assess the roles of these factors. |
|
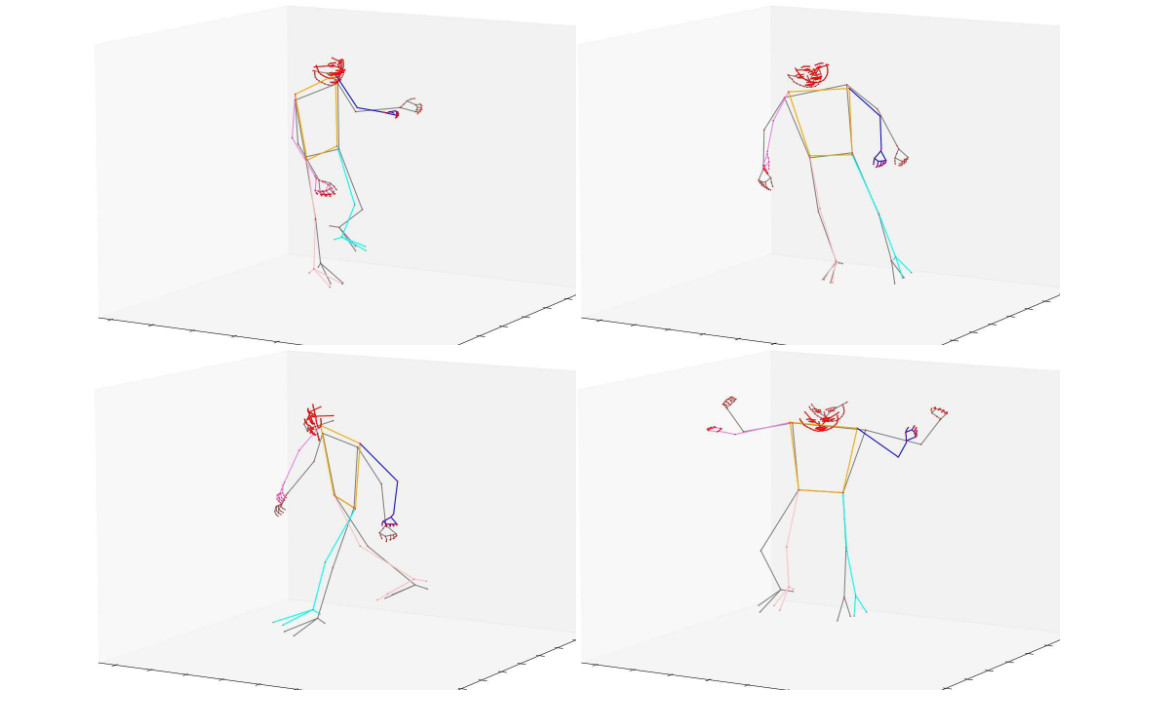
H3WB: Human3.6M 3D WholeBody Dataset and BenchmarkYue Zhu, Nermin Samet, David Picard ICCV, 2023 arxiv / code / 3D human whole-body pose estimation aims to localize precise 3D keypoints on the entire human body, including the face, hands, body, and feet. We introduce Human3.6M 3D WholeBody (H3WB) which provides whole-body annotations for the Human3.6M dataset using the COCO Wholebody layout. H3WB is a large scale dataset with 133 whole-body keypoint annotations on 100K images, made possible by our new multi-view pipeline. Along with H3WB, we propose 3 tasks: i) 3D whole-body pose lifting from 2D complete whole-body pose, ii) 3D whole-body pose lifting from 2D incomplete whole-body pose, iii) 3D whole-body pose estimation from a single RGB image. We also report several baselines from popular methods for these tasks. |
|
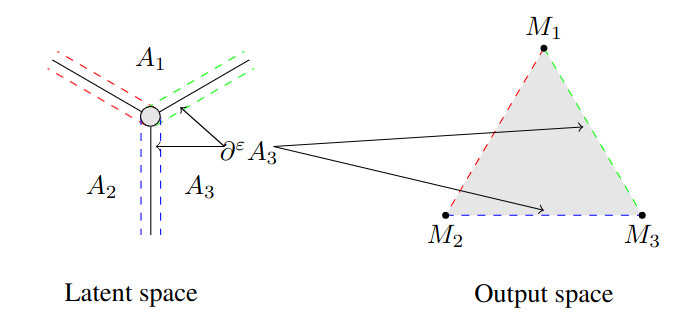
Unveiling the Latent Space Geometry of Push-Forward Generative ModelsThibaut Issenhuth, Ugo Tanielian, Jeremie Mary, David Picard ICML, 2023 arxiv / Many deep generative models are defined as a push-forward of a Gaussian measure by a continuous generator, such as Generative Adversarial Networks (GANs) or Variational Auto-Encoders (VAEs). This work explores the latent space of such deep generative models. A key issue with these models is their tendency to output samples outside of the support of the target distribution when learning disconnected distributions. We investigate the relationship between the performance of these models and the geometry of their latent space. Building on recent developments in geometric measure theory, we prove a sufficient condition for optimality in the case where the dimension of the latent space is larger than the number of modes. Through experiments on GANs, we demonstrate the validity of our theoretical results and gain new insights into the latent space geometry of these models. Additionally, we propose a truncation method that enforces a simplicial cluster structure in the latent space and improves the performance of GANs. |
|
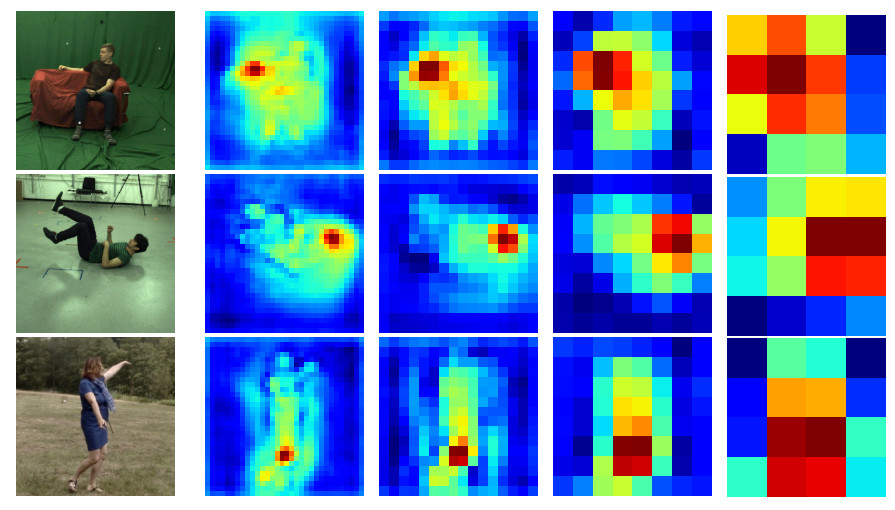
SSP-Net: Scalable sequential pyramid networks for real-Time 3D human pose regressionDiogo C Luvizon, Hedi Tabia, David Picard Pattern Recognition, 2023 arxiv / In this paper we propose a highly scalable convolutional neural network, end-to-end trainable, for real-time 3D human pose regression from still RGB images. We call this approach the Scalable Sequential Pyramid Networks (SSP-Net) as it is trained with refined supervision at multiple scales in a sequential manner. Our network requires a single training procedure and is capable of producing its best predictions at 120 frames per second (FPS), or acceptable predictions at more than 200 FPS when cut at test time. We show that the proposed regression approach is invariant to the size of feature maps, allowing our method to perform multi-resolution intermediate supervisions and reaching results comparable to the state-of-the-art with very low resolution feature maps. |

|
EdiBERT, a generative model for image editingThibaut Issenhuth, Ugo Tanielian, Jérémie Mary, David Picard TMLR, 2023 arxiv / code / In this paper, we aim at making a step towards a unified approach for image editing. To do so, we propose EdiBERT, a bi-directional transformer trained in the discrete latent space built by a vector-quantized auto-encoder. We argue that such a bidirectional model is suited for image manipulation since any patch can be re-sampled conditionally to the whole image. Using this unique and straightforward training objective, |
|
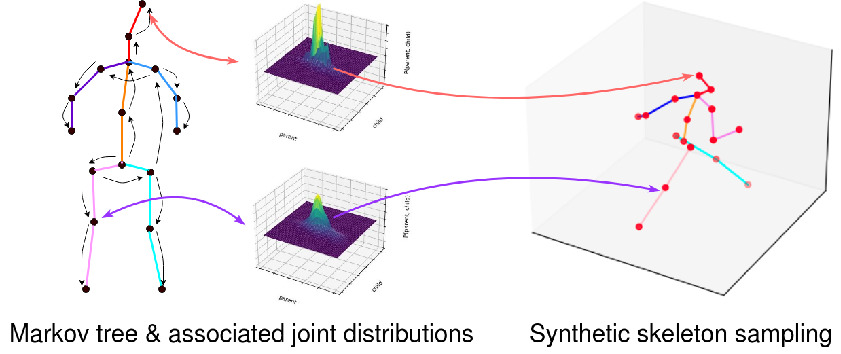
Decanus to Legatus: Synthetic training for 2D-3D human pose liftingYue Zhu, David Picard ACCV 2022, 2022 arxiv / code / We propose an algorithm to generate infinite 3D synthetic human poses (Legatus) from a 3D pose distribution based on 10 initial handcrafted 3D poses (Decanus) during the training of a 2D to 3D human pose lifter neural network. Our results show that we can achieve 3D pose estimation performance comparable to methods using real data from specialized datasets but in a zero-shot setup, showing the generalization potential of our framework. |
|
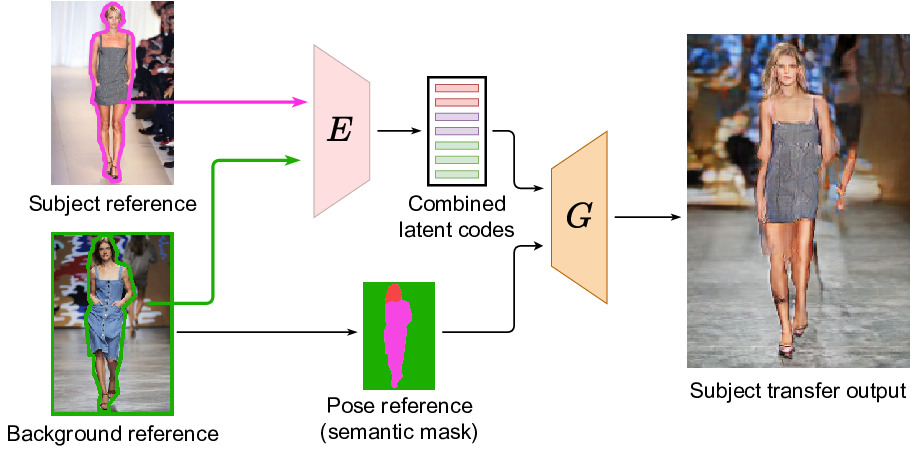
SCAM! Transferring Humans Between Images with Semantic Cross Attention ModulationNicolas Dufour, David Picard, Vicky Kalogeiton ECCV 2022, 2022 arxiv / code / We introduce SCAM (Semantic Cross Attention Modulation), a system that encodes rich and diverse information in each semantic region of the image (including foreground and background), thus achieving precise generation with emphasis on fine details. This is enabled by the Semantic Attention Transformer Encoder that extracts multiple latent vectors for each semantic region, and the corresponding generator that exploits these multiple latents by using semantic cross attention modulation. It is trained only using a reconstruction setup, while subject transfer is performed at test time. Our analysis shows that our proposed architecture is successful at encoding the diversity of appearance in each semantic region. |
|
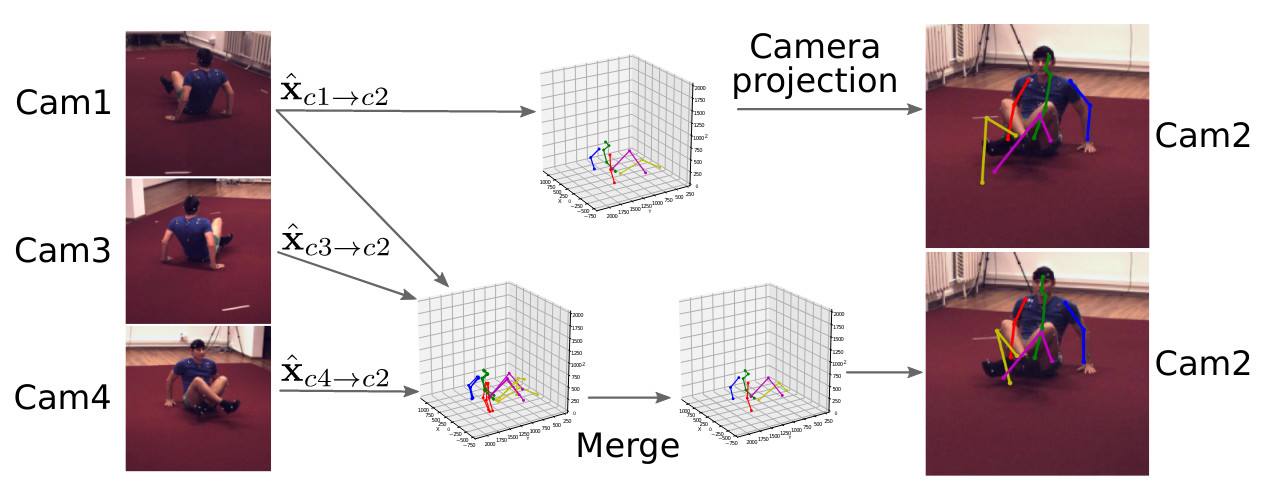
Consensus-based optimization for 3D human pose estimation in camera coordinatesDiogo C Luvizon, David Picard, Hedi Tabia International Journal of Computer Vision, 2022 arxiv / code / doi / 3D human pose estimation is frequently seen as the task of estimating 3D poses relative to the root body joint. Alternatively, we propose a 3D human pose estimation method in camera coordinates, which allows effective combination of 2D annotated data and 3D poses and a straightforward multi-view generalization. To that end, we cast the problem as a view frustum space pose estimation, where absolute depth prediction and joint relative depth estimations are disentangled. Final 3D predictions are obtained in camera coordinates by the inverse camera projection. Based on this, we also present a consensus-based optimization algorithm for multi-view predictions from uncalibrated images, which requires a single monocular training procedure. |
|
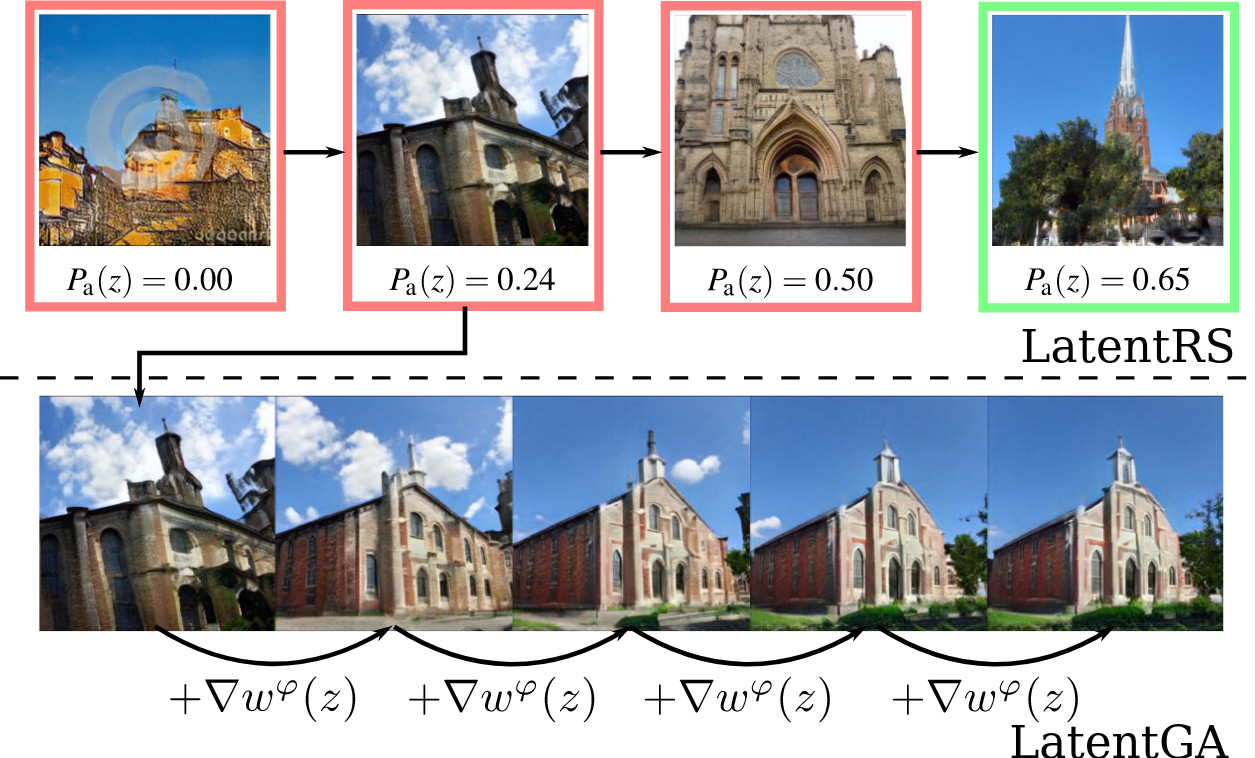
Latent reweighting, an almost free improvement for GANsThibaut Issenhuth, Ugo Tanielian, David Picard, Jérémie Mary IEEE/CVF Winter Conference on Applications of Computer Vision, 2022 arxiv / Standard formulations of GANs, where a continuous function deforms a connected latent space, have been shown to be misspecified when fitting different classes of images. In particular, the generator will necessarily sample some low-quality images in between the classes. Rather than modifying the architecture, a line of works aims at improving the sampling quality from pre-trained generators at the expense of increased computational cost. Building on this, we introduce an additional network to predict latent importance weights and two associated sampling methods to avoid the poorest samples. |
|
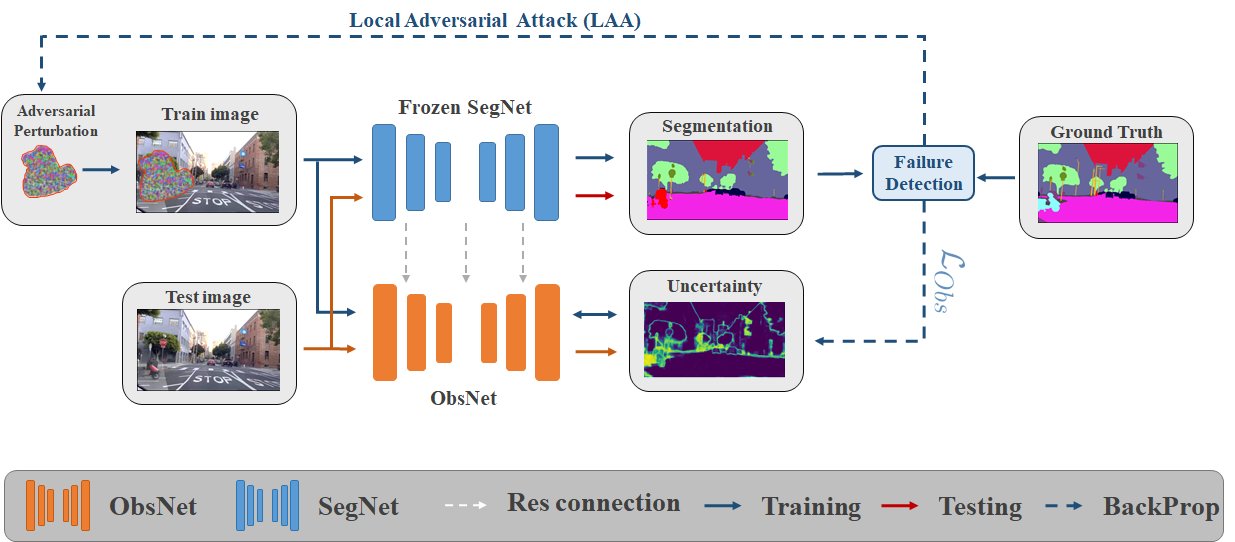
Triggering Failures: Out-of-Distribution Detection by Learning From Local Adversarial Attacks in Semantic SegmentationVictor Besnier, Andrei Bursuc, David Picard, Alexandre Briot International Conference on Computer Vision, 2021 arxiv / code / In this paper, we tackle the detection of out-of-distribution (OOD) objects in semantic segmentation. By analyzing the literature, we found that current methods are either accurate or fast but not both which limits their usability in real world applications. To get the best of both aspects, we propose to mitigate the common shortcomings by following four design principles: decoupling the OOD detection from the segmentation task, observing the entire segmentation network instead of just its output, generating training data for the OOD detector by leveraging blind spots in the segmentation network and focusing the generated data on localized regions in the image to simulate OOD objects. |
|
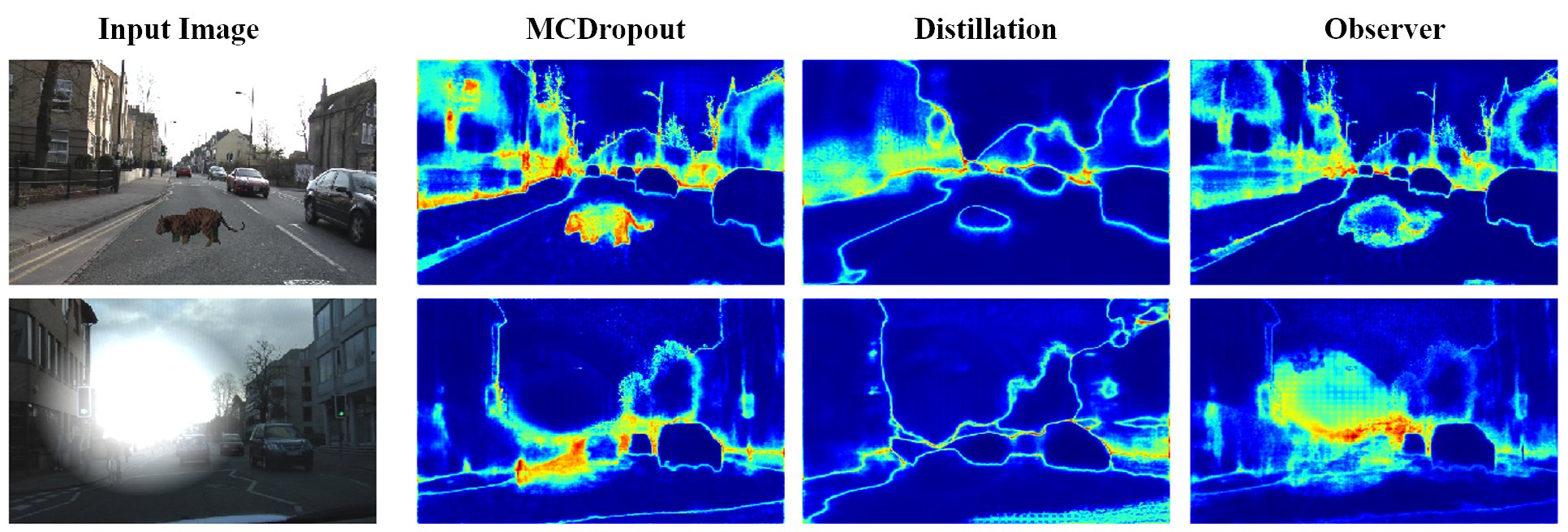
Learning Uncertainty for Safety-Oriented Semantic Segmentation in Autonomous DrivingVictor Besnier, David Picard, Alexandre Briot International Conference on Image Processing, 2021 arxiv / In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. |
|
DIABLO: Dictionary-based attention block for deep metric learningPierre Jacob, David Picard, Aymeric Histace, Edouard Klein Pattern Recognition Letters, 2020 arxiv / doi / In this paper, we propose DIABLO, a dictionary-based attention method for image embedding. DIABLO produces richer representations by aggregating only visually-related features together while being easier to train than other attention-based methods in deep metric learning. This is experimentally confirmed on four deep metric learning datasets (Cub-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval) for which DIABLO shows state-of-the-art performances. |

|
Multi-task Deep Learning for Real-Time 3D Human Pose Estimation and Action RecognitionDiogo Luvizon, David Picard, Hedi Tabia IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020 arxiv / doi / In this work, we propose a multi-task framework for jointly estimating 2D or 3D human poses from monocular color images and classifying human actions from video sequences. We show that a single architecture can be used to solve both problems in an efficient way and still achieves state-of-the-art or comparable results at each task while running with a throughput of more than 100 frames per second. The proposed method benefits from high parameters sharing between the two tasks by unifying still images and video clips processing in a single pipeline, allowing the model to be trained with data from different categories simultaneously and in a seamlessly way. |
|
Deepzzle: Solving Visual Jigsaw Puzzles with Deep Learning and Shortest Path OptimizationMarie-Morgane Paumard, David Picard, Hedi Tabia IEEE Transactions on Image Processing, 2020 doi / We tackle the image reassembly problem with wide space between the fragments, in such a way that the patterns and colors continuity is mostly unusable. The spacing emulates the erosion of which the archaeological fragments suffer. We use a two-step method to obtain the reassemblies: 1) a neural network predicts the positions of the fragments despite the gaps between them; 2) a graph that leads to the best reassemblies is made from these predictions. |

|
Human pose regression by combining indirect part detection and contextual informationDiogo Luvizon, David Picard, Hedi Tabia Computers and Graphics, 2019 arxiv / code / doi / In this paper, we tackle the problem of human pose estimation from still images, which is a very active topic, specially due to its several applications, from image annotation to human-machine interface. We use the soft-argmax function to convert feature maps directly to body joint coordinates, resulting in a fully differentiable framework. Our method is able to learn heat maps representations indirectly, without additional steps of artificial ground truth generation. |

|
Metric Learning With HORDE: High-Order Regularizer for Deep EmbeddingsPierre Jacob, David Picard, Aymeric Histace, Edouard Klein International Conference on Computer Vision, 2019 arxiv / code / In this paper, we tackle this scattering problem with a distribution-aware regularization named HORDE. This regularizer enforces visually-close images to have deep features with the same distribution which are well localized in the feature space. We provide a theoretical analysis supporting this regularization effect. We also show the effectiveness of our approach by obtaining state-of-the-art results on 4 well-known datasets (Cub-200-2011, Cars-196, Stanford Online Products and Inshop Clothes Retrieval). |
|
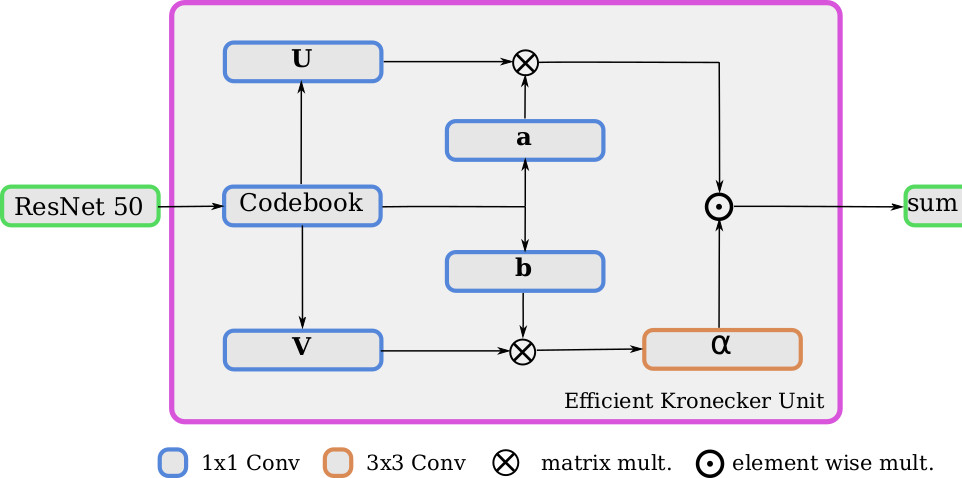
Efficient Codebook and Factorization for Second Order Representation LearningPierre Jacob, David Picard, Aymeric Histace, Edouard Klein International Conference on Image Processing, 2019 arxiv / To build richer representations, high order statistics have been exploited and have shown excellent performances, but they produce higher dimensional features. While this drawback has been partially addressed with factorization schemes, the original compactness of first order models has never been retrieved, or at the cost of a strong performance decrease. Our method, by jointly integrating codebook strategy to factorization scheme, is able to produce compact representations while keeping the second order performances with few additional parameters. |
|
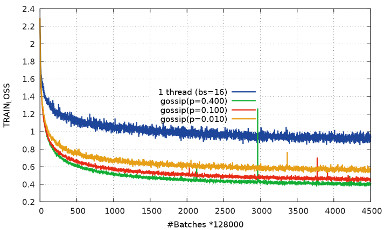
Distributed optimization for deep learning with gossip exchangeMichael Blot, David Picard, Nicolas Thome, Matthieu Cord Neurocomputing, 2019 arxiv / doi / We address the issue of speeding up the training of convolutional neural networks by studying a distributed method adapted to stochastic gradient descent. Our parallel optimization setup uses several threads, each applying individual gradient descents on a local variable. We propose a new way of sharing information between different threads based on gossip algorithms that show good consensus convergence properties. Our method called GoSGD has the advantage to be fully asynchronous and decentralized. |

|
Leveraging Implicit Spatial Information in Global Features for Image RetrievalPierre Jacob, David Picard, Aymeric Histace, Edouard Klein International Conference on Image Processing, 2018 arxiv / doi / Most image retrieval methods use global features that aggregate local distinctive patterns into a single representation. However, the aggregation process destroys the relative spatial information by considering orderless sets of local descriptors. We propose to integrate relative spatial information into the aggregation process by taking into account co-occurrences of local patterns in a tensor framework. |

|
Jigsaw Puzzle Solving Using Local Feature Co-Occurrences in Deep Neural NetworksMarie-Morgane Paumard, David Picard, Hedi Tabia International Conference on Image Processing, 2018 arxiv / doi / Archaeologists are in dire need of automated object reconstruction methods. Fragments reassembly is close to puzzle problems, which may be solved by computer vision algorithms. As they are often beaten on most image related tasks by deep learning algorithms, we study a classification method that can solve jigsaw puzzles. In this paper, we focus on classifying the relative position: given a couple of fragments, we compute their local relation (e.g. on top). We propose several enhancements over the state of the art in this domain, which is outperformed by our method by 25%. |

|
Image Reassembly Combining Deep Learning and Shortest Path ProblemMarie-Morgane PaumardDavid Picard, Hedi Tabia European Conference on Computer Vision, 2018 arxiv / doi / This paper addresses the problem of reassembling images from disjointed fragments. More specifically, given an unordered set of fragments, we aim at reassembling one or several possibly incomplete images. The main contributions of this work are: (1) several deep neural architectures to predict the relative position of image fragments that outperform the previous state of the art; (2) casting the reassembly problem into the shortest path in a graph problem for which we provide several construction algorithms depending on available information; (3) a new dataset of images taken from the Metropolitan Museum of Art (MET) dedicated to image reassembly for which we provide a clear setup and a strong baseline. |
|
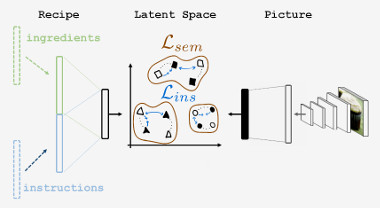
Cross-Modal Retrieval in the Cooking Context: Learning Semantic Text-Image EmbeddingsMicael Carvalho, Rémi Cadène, David Picard, Laure Soulier, Nicolas Thome, Matthieu Cord ACM SIGIR Conference on Research and Development in Information Retrieval, 2018 arxiv / doi / Designing powerful tools that support cooking activities has rapidly gained popularity due to the massive amounts of available data, as well as recent advances in machine learning that are capable of analyzing them. In this paper, we propose a cross-modal retrieval model aligning visual and textual data (like pictures of dishes and their recipes) in a shared representation space. We describe an effective learning scheme, capable of tackling large-scale problems, and validate it on the Recipe1M dataset containing nearly 1 million picture-recipe pairs. We show the effectiveness of our approach regarding previous state-of-the-art models and present qualitative results over computational cooking use cases. |
|
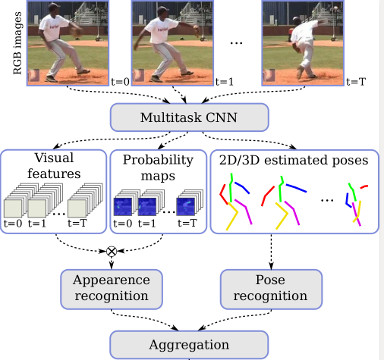
2D/3D Pose Estimation and Action Recognition using Multitask Deep LearningDiogo Luvizon, David Picard, Hedi Tabia IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018 arxiv / code / doi / Action recognition and human pose estimation are closely related but both problems are generally handled as distinct tasks in the literature. In this work, we propose a multitask framework for jointly 2D and 3D pose estimation from still images and human action recognition from video sequences. We show that a single architecture can be used to solve the two problems in an efficient way and still achieves state-of-the-art results. Additionally, we demonstrate that optimization from end-to-end leads to significantly higher accuracy than separated learning. The proposed architecture can be trained with data from different categories simultaneously in a seamlessly way. |
|
Design and source code from Jon Barron's website |